Query optimization is a process of defining the most efficient and optimal way and techniques that can be used to improve query performance based on the rational use of system resources and performance metrics. The purpose of query tuning is to find a way to decrease the response time of the query, prevent the excessive consumption of resources, and identify poor query performance.
In the context of query optimization, query processing identifies how to faster retrieve data from SQL Server by analyzing the execution steps of the query, optimization techniques, and other information about the query.
12 Query optimization tips for better performance
Monitoring metrics can be used to evaluate query runtime, detect performance pitfalls, and show how they can be improved. For example, they include:
- Execution plan: A SQL Server query optimizer executes the query step by step, scans indexes to retrieve data, and provides a detailed overview of metrics during query execution.
- Input/Output statistics: Used to identify the number of logical and physical reading operations during the query execution that helps users detect cache/memory capacity issues.
- Buffer cache: Used to reduce memory usage on the server.
- Latency: Used to analyze the duration of queries or operations.
- Indexes: Used to accelerate reading operations on the SQL Server.
- Memory-optimized tables: Used to store table data in memory to make reading and writing operations run faster.
Now, we’ll discuss the best SQL Server performance tuning practices and tips you may apply when writing SQL queries.
Tip 1: Add missing indexes
Table indexes in databases help retrieve information faster and more efficiently.
In SQL Server, when you execute a query, the optimizer generates an execution plan. If it detects the missing index that may be created to optimize performance, the execution plan suggests this in the warning section. With this suggestion, it informs you which columns the current SQL should be indexed, and how performance can be improved upon completion.
Let’s run the Query Profiler available in dbForge Studio for SQL Server to see how it works.
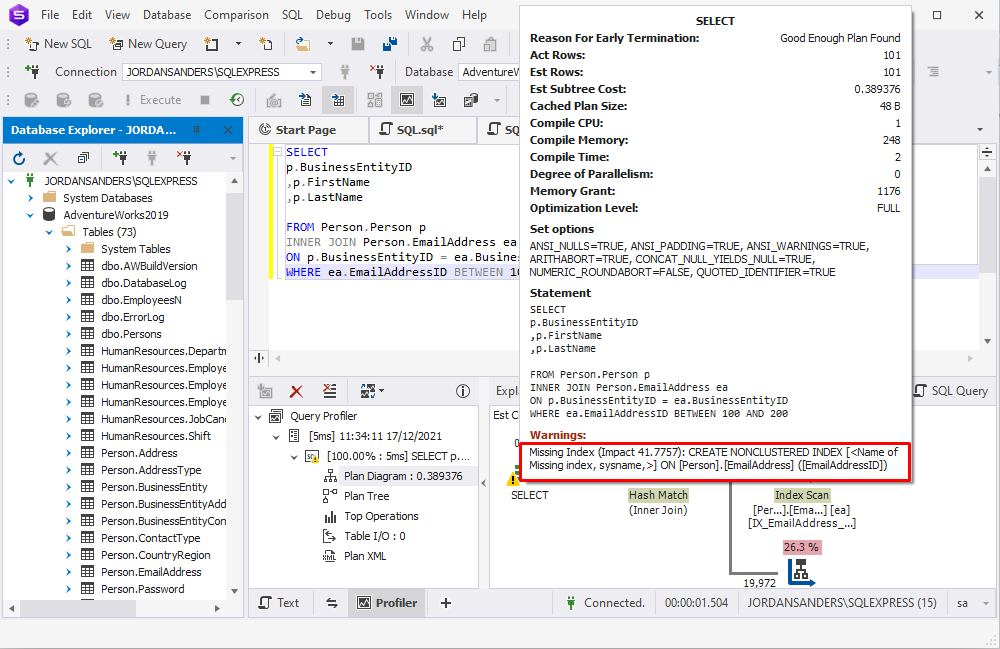
You can also understand which tables need indexes by analyzing graphical query plans. The thicker the arrow between operators on the query execution plan is, the more data is passed. Seeing thick arrows you need to think about adding indexes to the tables being processed to reduce the amount of data passed through the arrow.
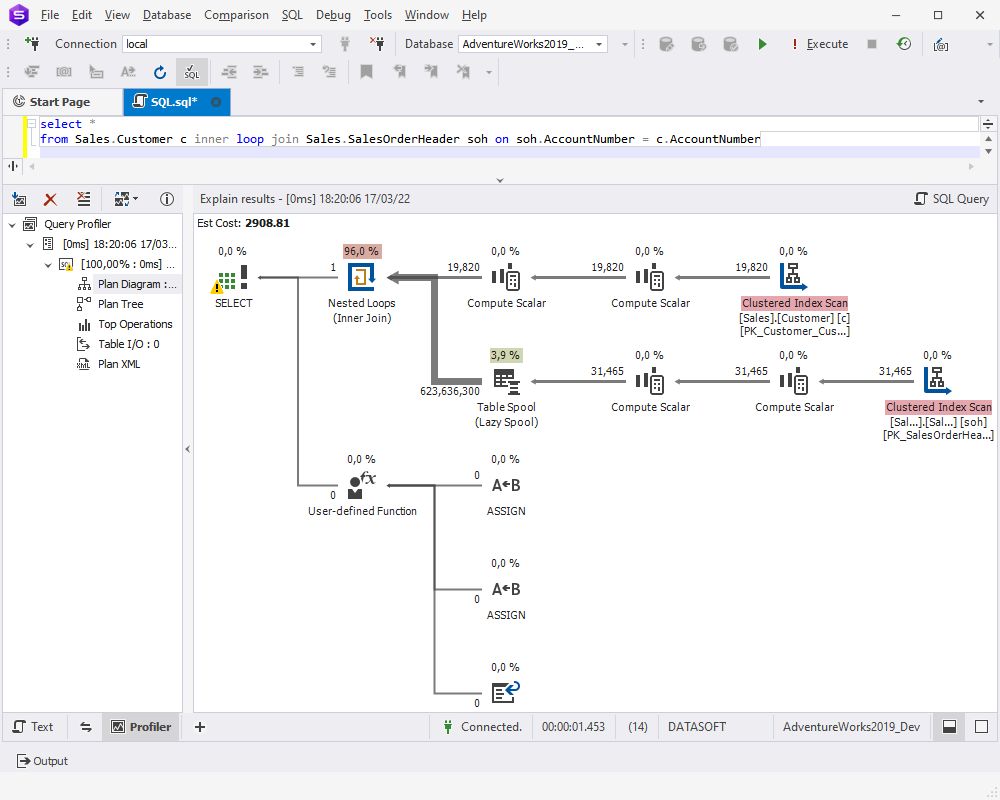
On the execution plan, you might encounter Table Spool (Lazy Spool in our case) that builds a temporary table in the tempdb and fills it in a lazy manner. Simply put, the table is filled by reading and storing the data only when individual rows are required by the parent operator. The Index Spool operator works in a somehow similar manner — all input rows are scanned and a copy of each row is placed in a hidden spool file that is stored in the tempdb database and exists only for the lifetime of the query. After that, an index on the rows is built. Both Table Spool and Index Spool might require optimization and adding indexes on the corresponding tables.
Nested Loops might also need your attention. Nested Loops must be indexed, as they take the first value from the first table and search for a match in the second table. Without indexes, SQL Server will have to scan and process the whole table, which can be time-consuming and resource-intensive.
Keep in mind that the missing index does not 100% guarantee better performance. In SQL Server, you can use the following dynamic management views to get a deep insight in using indexes based on query execution history:
- sys.dm_db_missing_index_details: Provides information about the suggested missing index, except for spatial indexes.
- sys.dm_db_missing_index_columns: Returns information about the table columns that do not contain indexes.
- sys.dm_db_missing_index_group_stats: Returns summary information about the missing index group, such as query cost, avg_user_impact (informs you how much performance can be improved by increasing the missing index), and some other metrics to measure effectiveness.
- sys.dm_db_missing_index_groups: Provides information about missing indexes included in a specific index group.
Tip 2: Check for unused indexes
You may encounter a situation where indexes exist but are not being used. One of the reasons for that might be implicit data type conversion. Let’s consider the following query:
SELECT *
FROM TestTable
WHERE IntColumn = '1';When executing this query, SQL Server will perform implicit data type conversion, i.e. convert int data to varchar and run the comparison only after that. In this case, indexes won’t be used. How can you avoid this? We recommend using the CAST() function that converts a value of any type into a specified datatype. Look at the query below.
SELECT *
FROM TestTable
WHERE IntColumn = CAST(@char AS INT);Let’s study one more example.
SELECT *
FROM TestTable
WHERE DATEPART(YEAR, SomeMyDate) = '2021';In this case, implicit data type conversion will take place too, and the indexes won’t be used. To avoid this, we can optimize the query in the following way:
SELECT *
FROM TestTable
WHERE SomeDate >= '20210101'
AND SomeDate < '20220101'Filtered indexes can affect performance too. Suppose, we have an index on the Customer table.
CREATE UNIQUE NONCLUSTERED INDEX IX ON Customer (MembershipCode)
WHERE MembershipCode IS NOT NULL;The index won’t work for the following query:
SELECT *
FROM Customer
WHERE MembershipCode = '258410';To make use of the index, you’ll need to optimize the query in the following way:
SELECT *
FROM Customer
WHERE MembershipCode = '258410'
AND MembershipCode IS NOT NULL;Tip 3: Avoid using multiple OR in the FILTER predicate
When you need to combine two or more conditions, it is recommended to eliminate the usage of the OR operator or split the query into parts separating search expressions. SQL Server can not process OR within one operation. Instead, it evaluates each component of the OR which, in turn, may lead to poor performance.
Let’s consider the following query.
SELECT *
FROM USER
WHERE Name = @P
OR login = @P;If we split this query into two SELECT queries and combine them by using the UNION operator, SQL Server will be able to make use of the indexes, and the query will be optimized.
SELECT * FROM USER
WHERE Name = @P
UNION
SELECT * FROM USER
WHERE login = @P;Tip 4: Use wildcards at the end of a phrase only
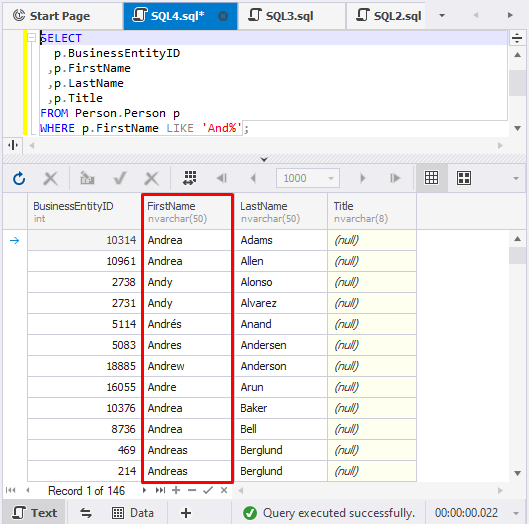
Wildcards in SQL Server work as a placeholder for words and phrases and can be added at the beginning/end of them. To make data retrieval faster and more efficient, you can use wildcards in the SELECT statement at the end of a phrase. For example:
SELECT
p.BusinessEntityID
,p.FirstName
,p.LastName
,p.Title
FROM Person.Person p
WHERE p.FirstName LIKE 'And%';As a result, the query will retrieve a list of customers whose First Name matches the specified condition, i.e. their First Name starts with ‘And’.
However, you might encounter situations where you regularly need to search by the last symbols of a word, number, or phrase — for example, by the last digits of a telephone number. In this case, we recommend creating a persisted computed column and running the REVERSE() function on it for easier back-searching.
CREATE TABLE dbo.Customer (
id INT IDENTITY PRIMARY KEY
,CardNo VARCHAR(128)
,ReversedCardNo AS REVERSE(CardNo) PERSISTED
)
GO
CREATE INDEX ByReversedCardNo ON dbo.Customer (ReversedCardNo)
GO
CREATE INDEX ByCardNo ON dbo.Customer (CardNo)
GO
INSERT INTO dbo.Customer (CardNo)
SELECT
NEWID()
FROM master.dbo.spt_values sv
SELECT TOP 100
*
FROM Customer c
--searching for CardNo that end in 510c
SELECT *
FROM dbo.Customer
WHERE CardNo LIKE '%510c'
SELECT
*
FROM dbo.Customer
WHERE ReversedCardNo LIKE REVERSE('%510c')Tip 5: Avoid too many JOINs
When you add multiple tables to a query and join them, you may overload the server. In addition, a large number of tables to retrieve data from may result in an inefficient execution plan. When generating a plan, the SQL query optimizer needs to identify how the tables are joined, in which order, and how and when to apply filters and aggregation.
All SQL experts are aware of the SQL JOINs importance, and understanding how to use them in queries appropriately is critical. In particular, JOIN elimination is one of the many techniques to achieve efficient query plans. You can split a single query into several separate queries which can later be joined, and thus remove unnecessary joins, subqueries, tables, etc.
Tip 6: Avoid using SELECT DISTINCT
The SQL DISTINCT operator is used to select only unique values of the column and thus eliminate duplicated values. It has the following syntax:
SELECT DISTINCT column_name FROM table_name;However, this may require the tool to process large volumes of data and as a result, make the query run slowly. Generally, it is recommended to avoid using SELECT DISTINCT and simply execute the SELECT statement but specify columns.
Another issue is that quite often people build JOINs unnecessarily, and when the data doubles, they add DISTINCT. This happens mainly in a leader-follower relation when people do SELECT DISTINCT … FROM LEADER JOIN FOLLOWER… instead of doing the correct SELECT … FROM LEADER WHERE EXISTS (SELECT… FROM FOLLOWER).
Tip 7: Use SELECT fields instead of SELECT *
The SELECT statement is used to retrieve data from the database. In the case of large databases, it is not recommended to retrieve all data because this will take more resources on querying a huge volume of data.
If we execute the following query, we will retrieve all data from the Users table, including, for example, users’ avatar pictures. The result table will contain lots of data and will take too much memory and CPU usage.
SELECT
*
FROM Users;Instead, you can specify the exact columns you need to get data from, thus, saving database resources. In this case, SQL Server will retrieve only the required data, and the query will have lower cost.
For example:
SELECT
FirstName
,LastName
,Email
,Login
FROM Users;If you need to retrieve this data regularly, for example, for authentication purposes, we recommend using covering indexes, the biggest advantage of which is that they contain all the fields required by query and can significantly improve query performance and guarantee better results.
CREATE NONCLUSTERED INDEX IDX_Users_Covering ON Users
INCLUDE (FirstName, LastName, Email, Login)Tip 8: Use TOP to sample query results
The SELECT TOP command is used to set a limit on the number of records to be returned from the database. To make sure that your query will output the required result, you can use this command to fetch several rows as a sample.
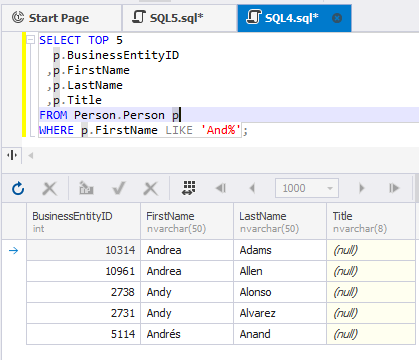
For example, take the query from the previous section and define the limit of 5 records in the result set.
SELECT TOP 5
p.BusinessEntityID
,p.FirstName
,p.LastName
,p.Title
FROM Person.Person p
WHERE p.FirstName LIKE 'And%';This query will retrieve only 5 records matching the condition:
Tip 9: Run the query during off-peak hours
Another SQL tuning technique is to schedule the query execution at off-peak hours, especially if you need to run multiple SELECT queries from large tables or execute complex queries with nested subqueries, looping queries, etc. If you are running a heavy query against a database, SQL Server locks the tables you are working with to prevent concurrent use of resources by different transactions. That means that other users are not able to work with those tables. Thus, executing heavy queries at peak times leads not only to server overload but also to restricting other users’ access to certain amounts of data. One of the popular mechanisms to avoid this is to use the WITH (NOLOCK) hint. It allows the user to retrieve the data without being affected by the locks. The biggest drawback of using WITH (NOLOCK) is that it may result in working with dirty data. We recommend that users should give preference to snapshot isolation which helps avoid data locking by using row versioning and guarantees that each transaction sees a consistent snapshot of the database.
Tip 10: Minimize the usage of any query hint
When you face performance issues, you may use query hints to optimize queries. They are specified in T-SQL statements and make the optimizer select the execution plan based on this hint. Usually, query hints include NOLOCK, Optimize For and Recompile. However, you should carefully consider their usage because sometimes they may cause more unexpected side effects, undesirable impacts, or even break business logic when trying to solve the issue. For example, you write additional code for the hints that can be inapplicable or obsolete after a while. This means that you should always monitor, manage, check, and keep hints up to date.
Tip 11: Minimize large write operations
Writing, modifying, deleting, or importing large volumes of data may impact query performance and even block the table when it requires updating and manipulating data, adding indexes or check constraints to queries, processing triggers, etc. In addition, writing a lot of data will increase the size of log files. Thus, large write operations may not be a huge performance issue, but you should be aware of their consequences and be prepared in case of unexpected behavior.
One of the best practices in optimizing SQL Server performance lies in using filegroups that allow you to spread your data across multiple physical disks. Thereby multiple write operations can be processed simultaneously and thus much faster.
Compression and data partitioning can also optimize performance and help minimize the cost of large write operations.
Tip 12: Create JOINs with INNER JOIN (not WHERE)
The SQL INNER JOIN statement returns all matching rows from joined tables, while the WHERE clause filters the resulting rows based on the specified condition. Retrieving data from multiple tables based on the WHERE keyword condition is called NON-ANSI JOINs while INNER JOIN belongs to ANSI JOINs.
It does not matter for SQL Server how you write the query – using ANSI or NON-ANSI joins – it’s just much easier to understand and analyze queries written using ANSI joins. You can clearly see where the JOIN conditions and the WHERE filters are, whether you missed any JOIN or filter predicates, whether you joined the required tables, etc.
Let’s see how to optimize a SQL query with INNER JOIN on a particular example. We are going to retrieve data from the tables HumanResources.Department and HumanResources.EmployeeDepartmentHistory where DepartmentIDs are the same. First, execute the SELECT statement with the INNER JOIN type:
SELECT
d.DepartmentID
,d.Name
,d.GroupName
FROM HumanResources.Department d
INNER JOIN HumanResources.EmployeeDepartmentHistory edh
ON d.DepartmentID = edh.DepartmentIDThen, use the WHERE clause instead of INNER JOIN to join the tables in the SELECT statement:
SELECT
d.Name
,d.GroupName
,d.DepartmentID
FROM HumanResources.Department d
,HumanResources.EmployeeDepartmentHistory edh
WHERE d.DepartmentID = edh.DepartmentIDBoth queries will output the following result:
SQL query optimization best practices
SQL Server performance tuning and SQL query optimization are some of the main aspects for database developers and administrators. They need to carefully consider the usage of specific operators, the number of tables on a query, the size of a query, its execution plan, statistics, resource allocation, and other performance metrics – all that may improve and tune query performance or make it worse.
For better query performance, we recommend using tips and techniques presented in the article, such as running queries at off-peak hours, creating indexes, retrieving data only for the specific columns, applying the correct filter, joins, and operators, as well as trying not to overload queries.
In addition, we propose some recommendations which may not directly relate to coding techniques, but they can still help you write precise and efficient SQL code.
Use uppercase for keywords
Keywords in SQL are generally case-insensitive. You can use lower case, upper case, or both mixed across all popular database management systems, including Microsoft SQL Server. However, it is recommended to use the upper case for keywords for improved code readability.
Although some developers may find it cumbersome to switch between upper and lower case while coding, modern SQL code formatting tools provide the functionality to configure case usage, text coloring, indents, and other options. These tools can automatically apply the preferable formatting while typing.
Write comments for your SQL code
Commenting on the code is optional, but it is highly recommended. Even if some code solutions seem obvious at the moment, what happens in a couple of months when you need to revisit it, especially after writing lots of other code for different modules or projects? This is especially important for your colleagues who will have to work with your code.
Another essential point is to review your existing comments whenever you make changes to your code, ensuring that they remain relevant. It may take time, but it greatly improves the readability of your code, and your efforts will pay off.
Use a professional SQL code editor
As a developer, you may apply various techniques and customize your workflows according to your preferences, but creating code manually from scratch consumes a lot of time and demands exceptional precision. A reliable and potent SQL editor makes code writing easier and enhances accuracy.
Modern SQL editors offer robust functionality for query development, such as auto-completion options, libraries of code snippets, syntax validation, and code formatting. Advanced tools for SQL development allow developers to double the coding speed twice (at least) and guarantee outstanding code quality.
Conclusion
In the article, we have covered a lot of fine-tuning techniques and tips to improve performance. We hope that they will work for you and help you avoid any performance issues that may arise.





0 comments:
Post a Comment
Note: only a member of this blog may post a comment.